5. 대규모 데이터 처리 실전 입문
14강. 용도특화형 인덱싱
인덱스와 시스템 구성
대규모 데이터를 다룰 경우, 전문 검색이나 유사문서계열 탐색, 데이터마이닝 같은 작업에서는 많은 경우 RDBMS로는 한계가 있습니다. 이런 경우에는 배치 처리로 RDBMS에서 데이터를 추출해서 별도의 인덱스 서버와 같은 것을 만들고, 이 인덱스 서버에 웹 애플리케이션에서 RPC(Remote Procedure Call) 등으로 액세스하는 방법을 사용합니다.
RPC, 웹 API
그림 5.1을 살펴보겠습니다. 우선 그림 5.1의 1️⃣ DB가 있습니다. 이 DB에서 정기적으로 3시간에 1번처럼 cron 등으로 데이터를 추출해서(❶) 2️⃣ 인덱스 서버로 넘깁니다. 인덱스로는 2️⃣에서 검색용 역 인덱스를 만들어줍니다(❷). 3️⃣ AP 서버에서는 인덱스를 갖고 있는 2️⃣ 인덱스 서버에 RPC로 액세스합니다(❸).
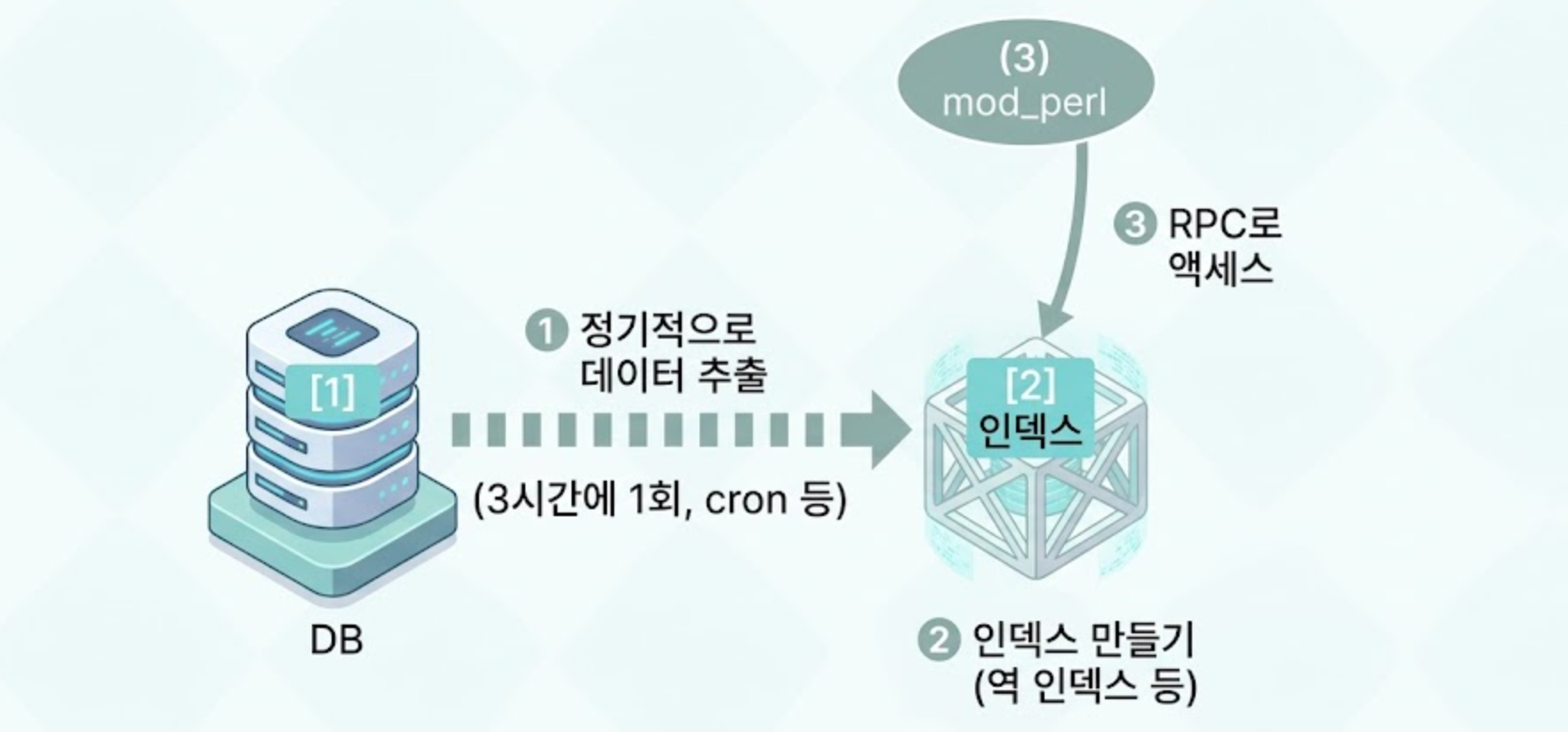
그림 5.1 하테나 북마크의 검색 시스템 이미지화 - RPC 버전
RPC는 Remote Procedure Call을 의미합니다. 요즘은 RPC보다는 웹 API라고 부르곤 합니다.
그림을 조금 바꿔보겠습니다(그림 5.2). 인덱스를 갖고 있는 그림 5.2의 2️⃣ 서버에 2️⃣' 웹 서버를 실행하고, 여기에 무언가를 검색해서 JSON을 반환하는 애플리케이션을 만들고(4️⃣), 3️⃣에서는 웹 API로 JSON에 액세스합니다. 4️⃣에 웹 API가 아니라 C++로 서버를 만들고 여기에 RPC를 하는 경우도 있는데, 사고방식은 같은 것입니다.
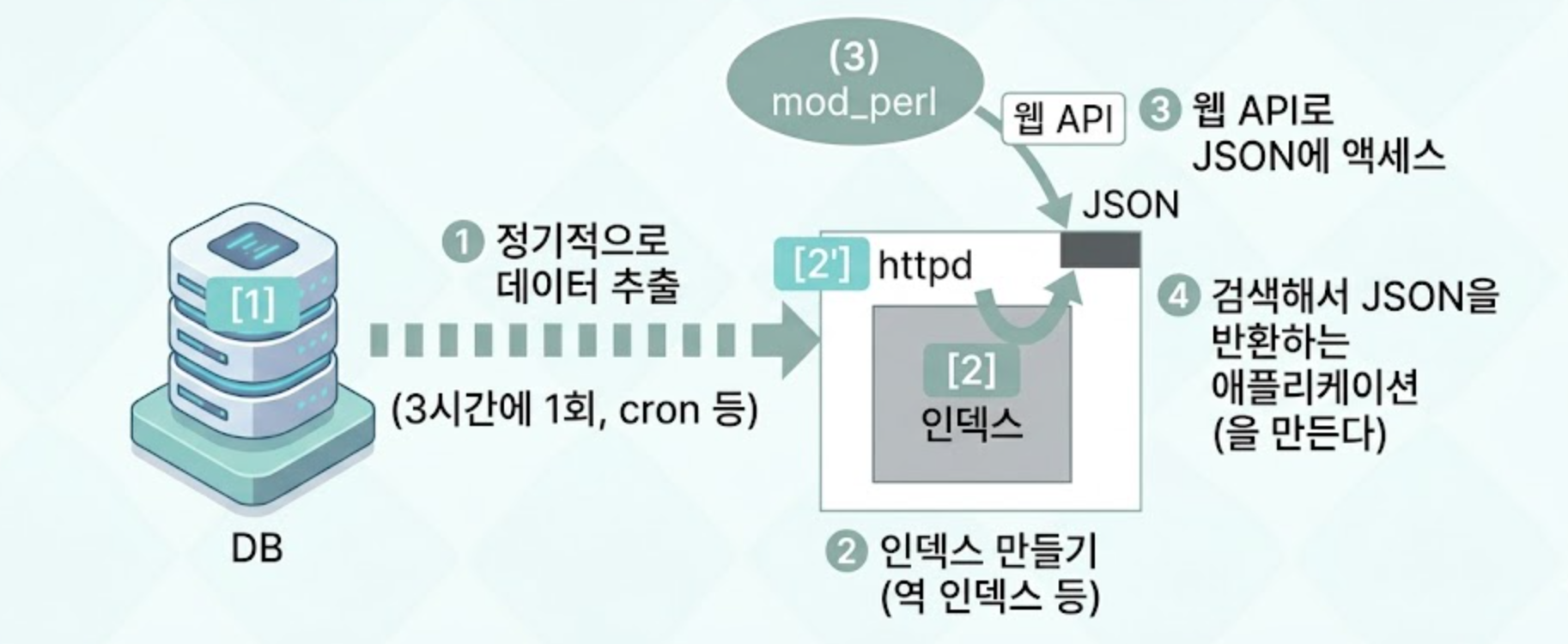
그림 5.2 하테나 북마크의 검색 시스템 이미지화 - 웹 API 버전
용도특화형 인덱싱
이상과 같은 방법을 하테나에서는 용도특화형 인덱싱이라고 합니다. 용도특화형 인덱싱을 하면 RDBMS에서는 어려운 일이 가능해집니다. 무언가 특정한 목적으로�만 사용하고자 할 때에는 특정한 목적만으로 사용할 수 있도록 튜닝한 데이터 구조를 사용하면 압도적으로 빠릅니다. 이것이 바로 용도특화형 인덱싱입니다.
검색에서 역 인덱스가 그 전형적인 예입니다. 자연언어처리와 같은 처리를 미리 한 다음 인덱스를 만들어두면, RDBMS로 데이터를 전부 순회하지 않아도 순식간에 검색할 수 있습니다.
예. 하테나 키워드에 의한 링크
특정 문서가 20만 이상의 키워드 중에 무엇을 포함하는지를 찾아야만 할 때, 일일이 DB 내에 있는 키워드 목록과 사용자가 작성한 내용을 맞춰보게 되면 DB에 과부하가 걸리게 됩니다. 그래서 배치 처리로 20만 건의 키워드를 추출해둡니다.
정규표현만으로는 힘들어서 안 되므로 현재는 Trie 기반의 정규표현을 사용해서 Common Prefix Search(공통접두사검색)를 수행합니다. Trie와 Common Prefix Search 조합은 매우 효과적입니다.
아울러서 Common Prefix Search를 할 때에는 Aho-Corasick법이나 Double Array Trie 등 다양한 알고리즘/데이터 구조가 있습니다. 이 알고리즘의 데이터 구조를 DB에서 사전에 추출해서 만들어두고 매칭하는 것이 키워드 링크의 방법입니다.
예. 하테나 북마크의 텍스트 분류기
하테나 북마크의 카테고리도 좋은 예입니다. 하테나 북마크는 과학·학문이나 컴퓨터·IT 등 기사의 카테고리를 자동분류하고 있습니다.
간단히 설명하자면, 여기에서는 Complement Naive Bayes라는 알고리즘을 사용해서 자동으로 기계학습을 통해 분류하고 있습니다. Complement Naive Bayes 알고리즘을 사용할 때에는 문서에 포함된 단어의 출현확률이 필요합니다. 실제로는 출현빈도만을 저장하는 서버를 가동해두고, 이 서버에 질의하면 순식간에 응답이 반환됩니다.
전문 검색엔진
전문(全文) 검색엔진은 이와 관련된 것 중 가장 좋은 예입니다. 여기에서는 아래 포인트를 어떻게 쿼리할 것인가가 문제가 됩니다.
- 대량의 데이터에서 검색하고자 합니다.
- 빠르게 검색하고자 합니다.
좋은 느낌(Feeling Lucky)과 같은 문서를 상위로 가져오고자 합니다.
세 번째 좋은 느낌(Feeling Lucky)에 해당하는 문장을 상위로 가져오는 것은 사실 가장 어렵습니다. 이를 위해서는 스코어링 처리를 수행합니다. 스코어링에서는 검색대상인 문서가 가지고 있는 다양한 정보를 복합적으로 이용합니다.
이것도 특정 칼럼으로만 정렬할 수 있는 RDBMS에서는 무리입니다. 반대로 검색 인덱스를 직접 만들면, 즉 전문 검색엔진을 직접 구현한다면 스코어링 알고리즘도 자유롭게 선택할 수 있으므로 검색결과를 나열하는 방��법은 RDBMS를 사용하는 것보다 훨씬 유연하게 구성할 수 있습니다.
15강. 이론과 실전 양쪽과의 싸움
요구되는 기술적 요건 규명하기
대규모 웹 애플리케이션에 있어서 이론과 실전
대규모 웹 애플리케이션을 개발, 운용하려고 하면 이론과 실전 모두를 하지 않으면 안 됩니다. 이론과 실전 사이에서 균형을 잘 맞춰 실행해가는 것이 하테나와 같은 회사에 요구되는 기술적 요건입니다.
컴퓨터의 문제에 이르는 길을 어떻게 발견할까?
또 하나 중요한 것은, 하고자 하는 것을 컴퓨터의 문제로 전환해서 해결에 이르는 길을 찾을 수 있는지 여부입니다. 그것만 발견되면 문제해결은 엔지니어링의 문제가 됩니다.
앞서 키워드로 링크하고 싶다는 이야기에서 Double Array Trie를 만들고 Common Prefix Search라는 알고리즘을 적용시켜 주면 잘 해결된다고 했습니다. 지금은 방식을 알고 있어서 금방 이해하지만, 키워드로 링크하고 싶다라는 실현하고자 하는 것만 머릿속에 있는 시점에는 어떤 방법이 좋은 방법인지 쉽게 이해할 수는 없습니다.
결국 알고리즘/데이터 구조로 무언가를 실행할 때는, 해당 알고리즘의 데이터 구조를 사용해서 어떤 게 가능한지를 어느 정도 머릿속에 넣어두지 않으면 이럴 때 바로 떠오르지 않습니다.
Wrap Up
대규모 데이터 처리에서는 RDBMS만으로 모든 요구를 감당하기보다, 목적에 맞게 튜닝된 별도 인덱스와 검색 시스템을 두는 접근이 중요합니다. 또한 실무에서는 구현하고 싶은 기능을 알고리즘과 데이터 구조의 문제로 정확히 바꿔낼 수 있어야 이론이 실제 시스템 설계와 성능 개선으로 이어집니다.
Summary
전문 검색, 유사문서 탐색, 데이터마이닝 같은 작업에서는 RDBMS만으로는 성능과 유연성 측면에서 한계가 드러나므로, 배치 처리로 데이터를 추출해 별도의 인�덱스 서버를 구축하는 방식이 유효합니다. 하테나에서는 이를 용도특화형 인덱싱이라고 부르며, 역 인덱스, Trie, Common Prefix Search, Aho-Corasick법, Double Array Trie 같은 알고리즘과 데이터 구조를 목적에 맞게 활용합니다. 또한 자동분류나 전문 검색처럼 스코어링과 확률 계산이 필요한 경우에도 전용 서버와 전용 인덱스 구조를 두는 편이 더 빠르고 유연합니다. 이런 실전 문제를 해결하려면 단순히 기능 요구를 이해하는 것을 넘어서, 그것을 어떤 계산 문제로 바꿀 수 있는지 파악해야 합니다. 결국 대규모 웹 애플리케이션에서는 이론과 실전 사이를 오가며 적절한 알고리즘과 시스템 구성을 선택하는 능력이 중요합니다.