4. 분산을 고려한 MySQL운용
11강. 인덱스를 올바르게 운용하기
분산을 고려한 MySQL 운용, 세 가지 포인트
분산을 고려한 MySQL 운용의 포인트는 세 가지입니다.
- 첫 번째 포인트는
OS 캐시 활용입니다. - 두 번째 포인트는
인덱스(index, 색인)입니다. - 세 번째 포인트는
확장을 한다는 전제로 시스템을 설계해둔다는 점입니다.
첫 번째 포인트인 OS 캐시 활용은 이전 장의 설명과 관련된 이야기로, 그 연장선상에 있습니다.
OS 캐시 활용
전체 데이터 크기에 주의해서 데이터량이 물리 메모리보다 가능한 한 적어지도록 유지합니다. 대량의 데이터를 저장하려는 테이블은 레코드가 가능한 한 작아지도록 컴팩트하게 설계하도록 합니다.
정수 int형은 32비트이므로 4바이트이고, 문자열은 8비트이므로 1바이트라는 기본적인 수치는 머리에 새겨둘 필요가 있습니다.
인덱스의 중요성
다음은 인덱스의 중요성에 대한 이야기입니다. 알고리즘·데이터 구조에서 탐색을 할 때는 기본적으로 트리(탐색트리)가 널리 사용됩니다. 인덱스는 주로 탐색을 빠르게 하기 위한 것으로, 그 내부 데이터 구조로는 트리가 사용됩니다.
MySQL의 인덱스는 기본적으로 B+트리(B Plus Tree)라는 데이터 구조입니다. B트리에 데이터를 삽입할 때는 일정한 규칙에 따라 삽입할 필요가 있는데, 그 규칙 덕분에 검색할 때 일부 노드를 순회하는 것만으로 자연스럽게 찾고자 하는 데이터에 도달하게 됩니다.
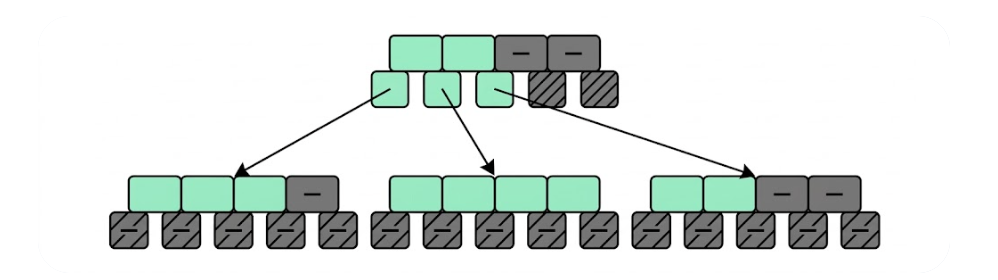
그림 4.2 B트리
트리에서 검색을 할 때는 노드에서 노드로 트리를 순회합니다. B트리의 경우 노드를 1블록에 모아서 저��장되도록 구성할 수 있으므로 디스크 Seek 발생 횟수를 노드를 찾아갈 때만으로 최소화할 수 있습니다.
MySQL에서 인덱스를 만들면 B트리의 변종인 B+트리에 의한 트리 데이터 구조가 생깁니다. 지금 살펴본 것처럼 탐색에서는 처음부터 실 데이터를 살펴가는 것보다 인덱스의 트리를 순회하는 편이 더 빠릅니다. 바로 이를 위한 구조를 만들어 주는 B트리(B+트리)는 이론적으로 탐색 계산량이 O(log n)으로 보장되므로, 선형탐색에서 O(n)으로 찾는 것보다 B트리로 찾는 게 더 빠릅니다. 이것이 바로 인덱스로 탐색하면 빨라지는 원리입니다.
인덱스의 효과
계산량 측면에서 개선될 뿐만 아니라 디스크 구조에 최적화된 인덱스를 사용해서 탐색함으로써 디스크 Seek 횟수 측면에서도 개선됩니다. 대규모가 되면 될수록 인덱스를 준비해놓느냐 아니냐에 따라 차이가 나게 됩니다.
사실 개인적인 용도의 작은 애플리케이션 정도라면 인덱스를 전혀 사용하지 않아도 충분한 속도로 동작합니다. 데이터 건수가 1,000건 정도라면 오히려 트리를 먼저 순회하는 오버헤드가 더 커서 그냥 처음부터 찾아 내려가는 편이 더 빠른 경우가 많습니다.
그러나 크기가 커지면 인덱스 없이는 시작부터 액세스할 수 없는 상황이 되므로 실로 인덱스는 중요합니다. 한편 MySQL은 레코드 총 건수를 보고 인덱스를 사용하지 않는 편이 더 빠르다고 판단되면, 사용하지 않는 최적화 작업을 내부에서 어느 정도 수행해줍니다.
12강. MySQL의 분산
MySQL의 레플리케이션 기능
MySQL에는 기본 기능으로 레플리케이션(replication) 기능이 있습니다. 레플리케이션이란 마스터(master)를 정하고(그림 4.6 ❶), 마스터를 뒤따르는 서버(slave)를 정해두면(그림 4.6 ❷), 마스터에 쓴 내용을 슬레이브가 폴링(polling)해서 동일한 내용으로 자신을 갱신하는 기능입니다(그림 4.6 ❸). 즉 슬레이브는 마스터의 레플리카(replica, 카피)가 되는 것입니다. 이렇게 해서 동일한 내용의 서버를 여러 대 마련할 수가 있습니다.
마스터/슬레이브로 레플리케이션해서 서버를 여러 대 준비하게 되면, 그림 4.6과 같은 구성으로 해서 AP 서버에서는 로드밸런서를 경유해서 슬레이브로 질의합니다. 이렇게 해서 쿼리를 여러 서버로 분산할 수 있습니다. 이때 애플리케이션 구현에서 select 등 참조 쿼리만 로드밸런서로 흘러가도록 합니다. 갱신 쿼리는 마스터로 직접 던집니다.
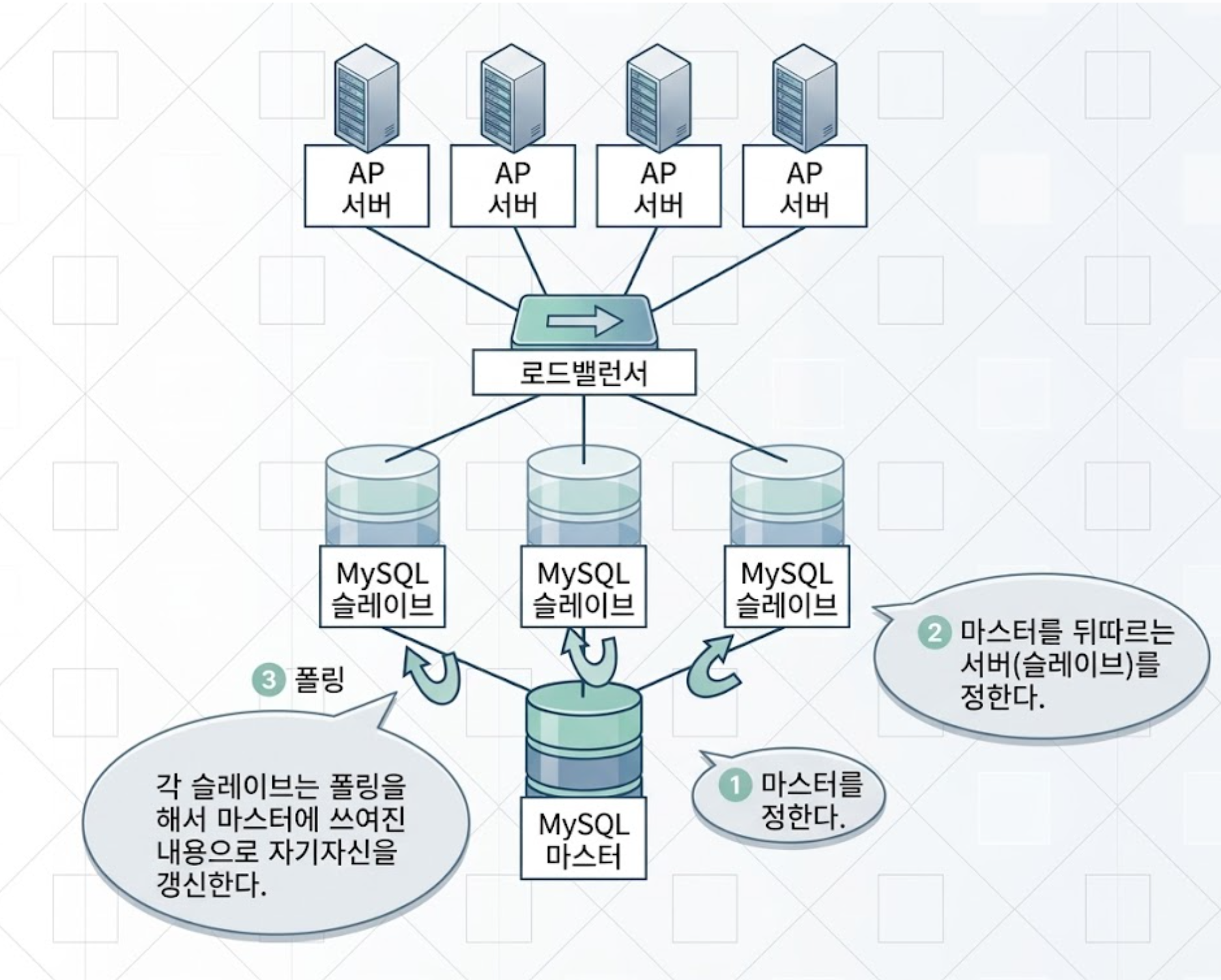
그림 4.6 MySQL의 레플리케이션 기능
마스터/슬레이브의 특징
앞의 그림 4.6을 다시 살펴보면, 이 구성에서는 마스터를 분산할 수 없다는 문제가 있습니다. 그리고 또 한 가지, 마스터의 다중화를 어떻게 할 것인가라는 문제도 당연히 발생합니다.
마스터는 확장할 수 없습니다. 반드시 할 수 없는 것은 아니지만, 갱신계열 쿼리가 늘어나면 상당히 험난해집니다. 그렇지만 이 부분에는 웹 애플리케이션의 특성이 있는데, 웹 애플리케이션에서는 대략 90% 이상이 참조계열 쿼리입니다. 따라서 웹 애플리케이션에서는 참조계열에 비하면 마스터가 병목이 되어 곤란한 상황이 발생하는 경우는 그렇게 많지 않습니다.
갱신/쓰기계열을 확장하고자 할 때
그러나 드물지만 마스터에 엄청난 쓰기작업이 발생하는 애플리케이션을 개발하는 경우가 있습니다. 예를 들어 책에서 말하는 발자국(足跡, footprint)과 같은 것은 요청 시마다 DB에 레코드를 써야 하고, 하테나 다이어리의 링크원(블로그의 리퍼러를 남기는 기능)도 요청이 올 때마다 어떤 링크를 통해 왔는지를 기록합니다.
이러한 것을 개발할 때 마스터의 테이블이 과부하에 걸리는 경우가 있습니다. 이런 경우에도 역시 테이블을 분할해서 테이블 크기를 작게 해줍니다. 그러면 분할로 인해 쓰기작업이 분산됩니다. 테이블 파일이 분산되면 동일 호스트 내에서 여러 디스크를 가지고 분산시킬 수도 있으며, 서로 다른 ��서버로 분산할 수도 있습니다.
처음부터 RDBMS를 사용하지 않는 방법도 생각해볼 수 있습니다. 단순히 값을 저장하고 꺼낼 뿐이므로 RDB가 갖는 복잡한 통계처리나 범용적인 정렬처리가 필요하지 않다면, key-value 스토어는 오버헤드도 적고 압도적으로 빠르며 확장하기 쉽습니다.
13강. MySQL의 스케일아웃과 파티셔닝
파티셔닝(테이블 분할)에 관한 보충
파티셔닝(테이블 분할)이란 테이블 A와 테이블 B를 서로 다른 서버에 놓아서 분산하는 방법입니다. 강의 10에서 설명한 것처럼, 파티셔닝은 국소성을 활용해서 분산할 수 있으므로 캐시가 유효하고, 그래서 파티셔닝은 효과적입니다.
파티셔닝을 전제로 한 설계
파티셔닝에 관해 또 하나 잊어서는 안 될 것이 파티셔닝을 전제로 한 설계입니다.
하테나 북마크의 테이블은 entry와 tag가 ��나뉘어 있습니다. 가끔 이 두 테이블을 함께 사용하고자 할 경우가 있습니다. 예를 들면 어떤 태그를 포함하는 엔트리 목록을 뽑고자 한다고 하겠습니다. 그러려면 JOIN 쿼리를 던져야 하지만, 이를 위해서는 위 두 개를 분리할 수 없습니다.
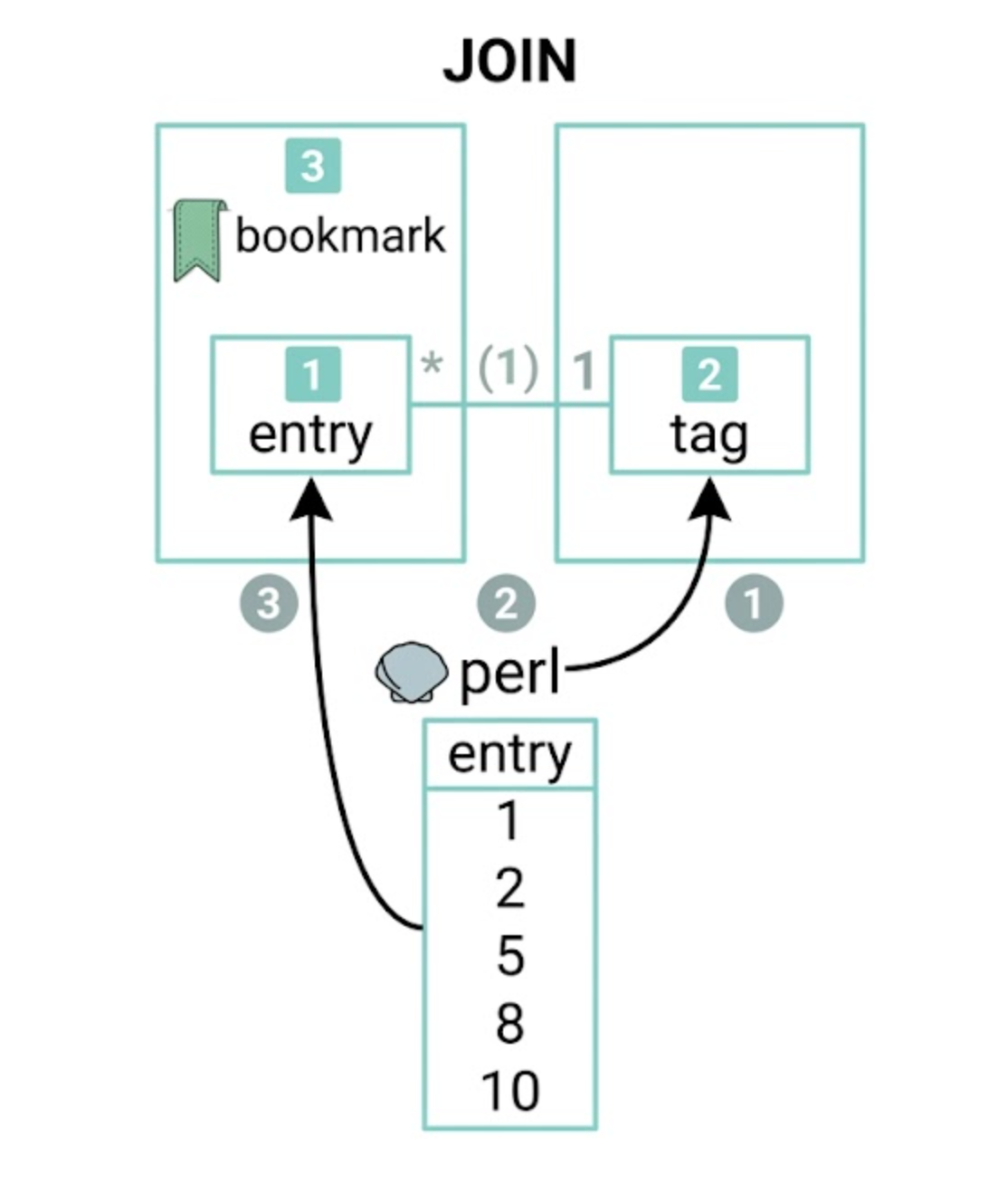
그림 4.9 MySQL과 JOIN
그림 4.9의 1️⃣ entry 테이블과 2️⃣ tag 테이블을 다른 머신에 올리고 싶어도, MySQL에는 서로 다른 서버에 있는 테이블을 JOIN하는 기능이 기본적으로는 없습니다. 그러므로 JOIN을 사용한다면 tag 테이블과 entry 테이블을 다른 서버에 위치시킬 수 없습니다.
따라서 기본적으로 JOIN 쿼리는 대상이 되는 테이블을 앞으로도 서버 분할하지 않을 것이라고 보장할 수 있을 때에만 사용합니다. entry와 bookmark 테이블, 이 둘은 상당히 긴밀하게 결합하고 있는 테이블이므로 애플리케이션 설계 측면에서는 다른 서버로 나눈다는 것은 있을 수 없습니다. 그러므로 1️⃣ entry와 3️⃣ bookmark 테이블은 함께 놓고 JOIN하고 있습니다.
다만 2️⃣ tag와 1️⃣ entry 테이블은 그다지 밀접하게 결합하고 있지 않고, 테이블의 데이터 크기를 볼 때 반드시 분할해야 한다는 것을 알고 있으므로 JOIN하지 않는 방침을 취하고 있습니다.
파티셔닝의 상반관계
파티셔닝의 좋은 점은 부하가 내려가고 국소성이 늘어나서 캐시 효과가 높아진다는 점입니다. 한편으로는 나쁜 점도 물론 있습니다.
운용이 복잡해진다
우선 운용이 복잡해집니다. 앞서 그림 4.9의 entry와 tag처럼 서버가 둘로 나뉘어지고, 게다가 용도가 다른 서버가 생깁니다. 같은 하테나 북마크의 DB지만 이 서버는 무슨 일을 하고 저 서버는 무슨 일을 하는지를 머릿속으로 파악해야 하므로 운용이 상당히 복잡해집니다. 그래서 하테나 다이어리에서 장애가 발생하면 어디서 고장이 났는지를 찾는 것만 해도 필사적입니다. 운용이 복잡해지면 결국 복구에 시간이 더 걸리게 됩니다.
고장률이 높아진다
대수가 늘어나는 만큼 고장확률이 높아지는 문제도 있습니다. 내장애성을 생각할 때 중요한 점은, 분할과 동반해서 머신을 늘릴 때는 1대만 늘려서는 끝나지 않는다는 것입니다.
다중화에 필요한 서버 대수
마스터가 1대 있고 슬레이브가 3대로 그림 4.13 1️⃣과 같이 다중화하는 구성을 생각해보겠습니다. 그렇��게 하면 슬레이브가 1대 고장 나더라도 괜찮을 뿐 아니라, 마스터가 고장 나더라도 슬레이브가 살아 있으므로 슬레이브 중 1대를 마스터로 해주면 OK입니다(그림 4.13 ❶').
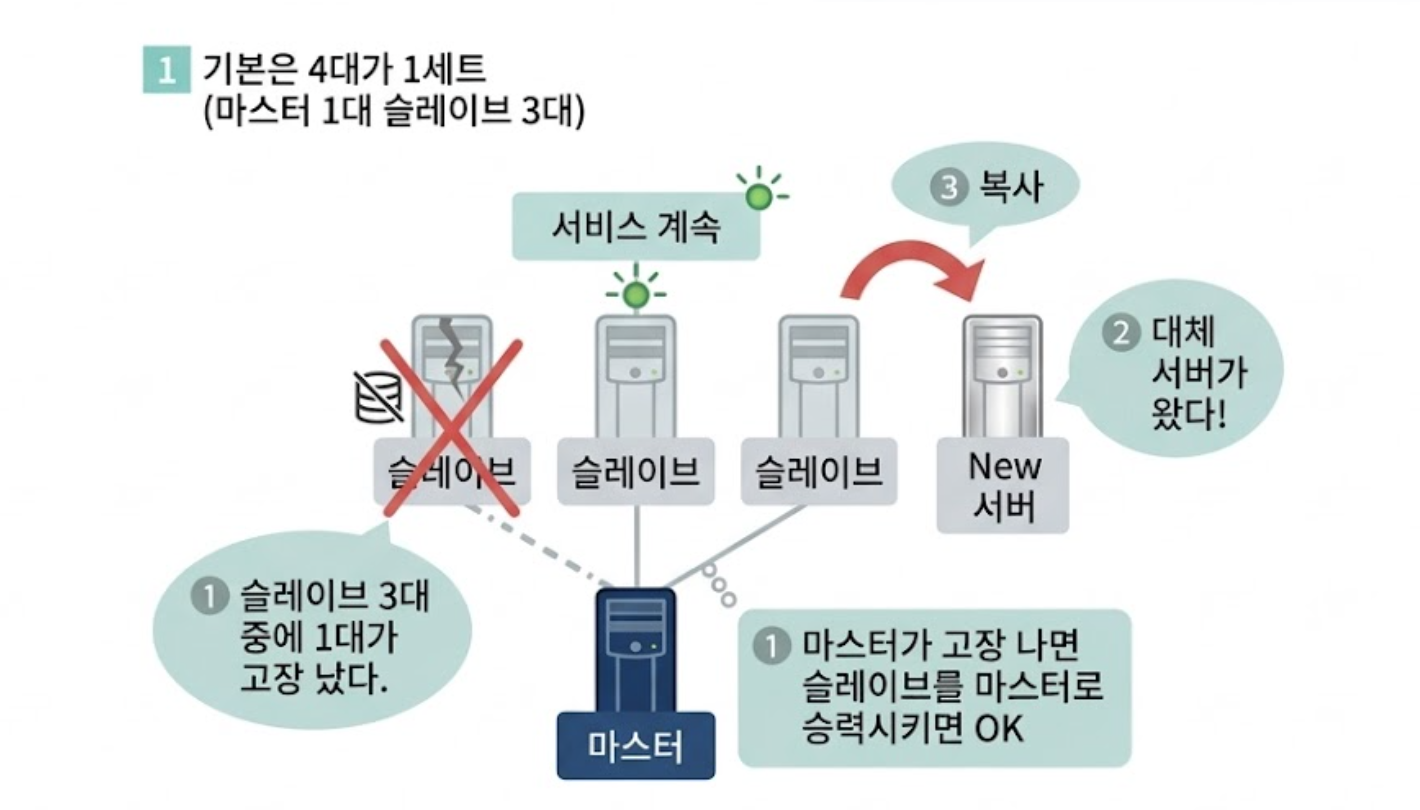
그림 4.13 마스터/슬레이브의 다중화
그러나 그림 4.13 1️⃣과 같이 슬레이브가 3대가 있으면, 1대가 고장 나더라도 남은 2대 중에 1대를 중지하고 새로운 서버로 데이터를 복사해서 고장 난 슬레이브 이외의 슬레이브 3대를 정리해서 복구할 수 있습니다. 이렇게 해서 무정지 복구를 할 수 있습니다. 따라서 다중화를 완벽하게 고려하자면 4대 1세트로 생각할 필요가 있습니다.
서버 대수와 고장률
그러므로 분할하면 대수가 한꺼번에 늘어나게 됩니다. 그렇게 되면 당연히 고장확률도 올라가고 여기저기서 고장이 발생합니다. 그러므로 제품의 가격대를 생각해볼 필요가 있으며, 분할하더라도 어느 쪽이 더 저렴할지, 어느 쪽이 더 운용하기 편한지를 빈틈없이 생각할 필요가 있습니다.
Wrap Up
분산 환경의 MySQL 운용에서는 OS 캐시 활용, 인덱스 설계, 그리고 확장을 전제로 한 데이터베이스 설계가 함께 맞물립니다. 특히 읽기 부하는 레플리케이션으로 분산할 수 있지만, 쓰기 부하와 JOIN 제약은 결국 파티셔닝 전제 설계와 운영 복잡도까지 함께 고려해야 한다는 점이 핵심입니다.
Summary
인덱스는 MySQL에서 기본적으로 B+트리 구조로 동작하며, 탐색 계산량을 O(log n) 수준으로 낮추고 디스크 Seek 횟수도 줄여 대규모 데이터에서 큰 차이를 만듭니다. MySQL의 레플리케이션은 마스터/슬레이브 구성을 통해 참조계열 쿼리를 분산하는 데 효과적이지만, 마스터 자체의 확장과 쓰기 부하 분산에는 한계가 있습니다. 그래서 쓰기 부하가 큰 시스템에서는 테이블 분할이나 key-value 스토어 같은 선택지도 함께 검토해야 합니다. 또한 파티셔닝은 캐시 효율과 부하 분산 측면에서는 유효하지만, 서버 간 JOIN 불가, 운영 복잡성 증가, 장애 확률 상승 같은 상반관계를 동반합니다. 결국 분산을 고려한 MySQL 운용은 쿼리 구조, 테이블 결합도, 서버 대수, 복구 전략까지 미리 설계하는 것이 중요합니다.